

{kind=link}
Over the previous few years, tuning-based diffusion fashions have demonstrated exceptional progress throughout a big selection of picture personalization and customization duties. Nevertheless, regardless of their potential, present tuning-based diffusion fashions proceed to face a number of advanced challenges in producing and producing style-consistent photos, and there could be three causes behind the identical. First, the idea of fashion nonetheless stays broadly undefined and undetermined, and includes a mixture of components together with ambiance, construction, design, materials, shade, and way more. Second inversion-based strategies are vulnerable to model degradation, leading to frequent lack of fine-grained particulars. Lastly, adapter-based approaches require frequent weight tuning for every reference picture to keep up a steadiness between textual content controllability, and elegance depth.
Moreover, the first objective of a majority of fashion switch approaches or model picture technology is to make use of the reference picture, and apply its particular model from a given subset or reference picture to a goal content material picture. Nevertheless, it’s the vast variety of attributes of fashion that makes the job troublesome for researchers to gather stylized datasets, representing model accurately, and evaluating the success of the switch. Beforehand, fashions and frameworks that take care of fine-tuning based mostly diffusion course of, fine-tune the dataset of photos that share a standard model, a course of that’s each time-consuming, and with restricted generalizability in real-world duties since it’s troublesome to assemble a subset of photos that share the identical or almost similar model.
On this article, we are going to discuss InstantStyle, a framework designed with the intention of tackling the problems confronted by the present tuning-based diffusion fashions for picture technology and customization. We are going to speak concerning the two key methods carried out by the InstantStyle framework:
- A easy but efficient method to decouple model and content material from reference photos throughout the characteristic area, predicted on the belief that options throughout the identical characteristic area will be both added to or subtracted from each other.
- Stopping model leaks by injecting the reference picture options solely into the style-specific blocks, and intentionally avoiding the necessity to use cumbersome weights for fine-tuning, typically characterizing extra parameter-heavy designs.
This text goals to cowl the InstantStyle framework in depth, and we discover the mechanism, the methodology, the structure of the framework together with its comparability with state-of-the-art frameworks. We may even discuss how the InstantStyle framework demonstrates exceptional visible stylization outcomes, and strikes an optimum steadiness between the controllability of textual components and the depth of fashion. So let’s get began.
Diffusion based mostly textual content to picture generative AI frameworks have garnered noticeable and memorable success throughout a big selection of customization and personalization duties, notably in constant picture technology duties together with object customization, picture preservation, and elegance switch. Nevertheless, regardless of the current success and increase in efficiency, model switch stays a difficult process for researchers owing to the undetermined and undefined nature of fashion, typically together with a wide range of components together with ambiance, construction, design, materials, shade, and way more. With that being mentioned, the first objective of stylized picture technology or model switch is to use the particular model from a given reference picture or a reference subset of photos to the goal content material picture. Nevertheless, the vast variety of attributes of fashion makes the job troublesome for researchers to gather stylized datasets, representing model accurately, and evaluating the success of the switch. Beforehand, fashions and frameworks that take care of fine-tuning based mostly diffusion course of, fine-tune the dataset of photos that share a standard model, a course of that’s each time-consuming, and with restricted generalizability in real-world duties since it’s troublesome to assemble a subset of photos that share the identical or almost similar model.
With the challenges encountered by the present method, researchers have taken an curiosity in growing fine-tuning approaches for model switch or stylized picture technology, and these frameworks will be cut up into two totally different teams:
- Adapter-free Approaches: Adapter-free approaches and frameworks leverage the ability of self-attention throughout the diffusion course of, and by implementing a shared consideration operation, these fashions are able to extracting important options together with keys and values from a given reference model photos instantly.
- Adapter-based Approaches: Adapter-based approaches and frameworks then again incorporate a light-weight mannequin designed to extract detailed picture representations from the reference model photos. The framework then integrates these representations into the diffusion course of skillfully utilizing cross-attention mechanisms. The first objective of the mixing course of is to information the technology course of, and to make sure that the ensuing picture is aligned with the specified stylistic nuances of the reference picture.
Nevertheless, regardless of the guarantees, tuning-free strategies typically encounter a number of challenges. First, the adapter-free method requires an alternate of key and values throughout the self-attention layers, and pre-catches the important thing and worth matrices derived from the reference model photos. When carried out on pure photos, the adapter-free method calls for the inversion of picture again to the latent noise utilizing methods like DDIM or Denoising Diffusion Implicit Fashions inversion. Nevertheless, utilizing DDIM or different inversion approaches may consequence within the lack of fine-grained particulars like shade and texture, due to this fact diminishing the model data within the generated photos. Moreover, the extra step launched by these approaches is a time consuming course of, and may pose important drawbacks in sensible purposes. However, the first problem for adapter-based strategies lies in placing the proper steadiness between the context leakage and elegance depth. Content material leakage happens when a rise within the model depth leads to the looks of non-style components from the reference picture within the generated output, with the first level of issue being separating types from content material throughout the reference picture successfully. To handle this concern, some frameworks assemble paired datasets that symbolize the identical object in several types, facilitating the extraction of content material illustration, and disentangled types. Nevertheless, because of the inherently undetermined illustration of fashion, the duty of making large-scale paired datasets is restricted when it comes to the range of types it may seize, and it’s a resource-intensive course of as effectively.
To deal with these limitations, the InstantStyle framework is launched which is a novel tuning-free mechanism based mostly on current adapter-based strategies with the power to seamlessly combine with different attention-based injecting strategies, and reaching the decoupling of content material and elegance successfully. Moreover, the InstantStyle framework introduces not one, however two efficient methods to finish the decoupling of fashion and content material, reaching higher model migration with out having the necessity to introduce extra strategies to realize decoupling or constructing paired datasets.
Moreover, prior adapter-based frameworks have been used broadly within the CLIP-based strategies as a picture characteristic extractor, some frameworks have explored the potential of implementing characteristic decoupling throughout the characteristic area, and in comparison towards undetermination of fashion, it’s simpler to explain the content material with textual content. Since photos and texts share a characteristic area in CLIP-based strategies, a easy subtraction operation of context textual content options and picture options can scale back content material leakage considerably. Moreover, in a majority of diffusion fashions, there’s a specific layer in its structure that injects the model data, and accomplishes the decoupling of content material and elegance by injecting picture options solely into particular model blocks. By implementing these two easy methods, the InstantStyle framework is ready to clear up content material leakage issues encountered by a majority of current frameworks whereas sustaining the power of fashion.
To sum it up, the InstantStyle framework employs two easy, simple but efficient mechanisms to realize an efficient disentanglement of content material and elegance from reference photos. The Immediate-Fashion framework is a mannequin impartial and tuning-free method that demonstrates exceptional efficiency in model switch duties with an enormous potential for downstream duties.
Immediate-Fashion: Methodology and Structure
As demonstrated by earlier approaches, there’s a steadiness within the injection of fashion situations in tuning-free diffusion fashions. If the depth of the picture situation is simply too excessive, it’d lead to content material leakage, whereas if the depth of the picture situation drops too low, the model might not look like apparent sufficient. A significant purpose behind this commentary is that in a picture, the model and content material are intercoupled, and because of the inherent undetermined model attributes, it’s troublesome to decouple the model and intent. Consequently, meticulous weights are sometimes tuned for every reference picture in an try to steadiness textual content controllability and power of fashion. Moreover, for a given enter reference picture and its corresponding textual content description within the inversion-based strategies, inversion approaches like DDIM are adopted over the picture to get the inverted diffusion trajectory, a course of that approximates the inversion equation to rework a picture right into a latent noise illustration. Constructing on the identical, and ranging from the inverted diffusion trajectory together with a brand new set of prompts, these strategies generate new content material with its model aligning with the enter. Nevertheless, as proven within the following determine, the DDIM inversion method for actual photos is commonly unstable because it depends on native linearization assumptions, leading to propagation of errors, and results in lack of content material and incorrect picture reconstruction.

Coming to the methodology, as a substitute of using advanced methods to disentangle content material and elegance from photos, the Immediate-Fashion framework takes the only method to realize comparable efficiency. In comparison towards the underdetermined model attributes, content material will be represented by pure textual content, permitting the Immediate-Fashion framework to make use of the textual content encoder from CLIP to extract the traits of the content material textual content as context representations. Concurrently, the Immediate-Fashion framework implements CLIP picture encoder to extract the options of the reference picture. Making the most of the characterization of CLIP world options, and publish subtracting the content material textual content options from the picture options, the Immediate-Fashion framework is ready to decouple the model and content material explicitly. Though it’s a easy technique, it helps the Immediate-Fashion framework is kind of efficient in preserving content material leakage to a minimal.
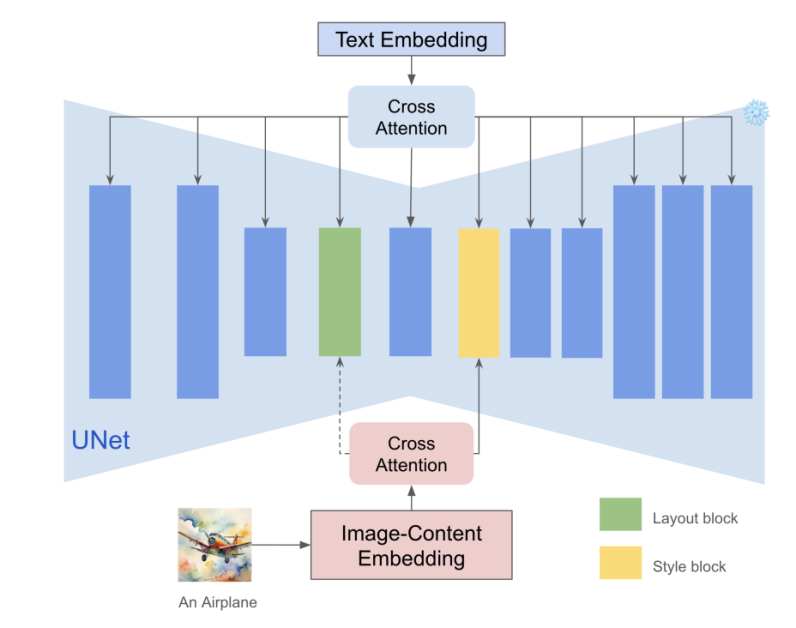
Moreover, every layer inside a deep community is accountable for capturing totally different semantic data, and the important thing commentary from earlier fashions is that there exist two consideration layers which can be accountable for dealing with model. up Particularly, it’s the blocks.0.attentions.1 and down blocks.2.attentions.1 layers accountable for capturing model like shade, materials, ambiance, and the spatial format layer captures construction and composition respectively. The Immediate-Fashion framework makes use of these layers implicitly to extract model data, and prevents content material leakage with out dropping the model power. The technique is easy but efficient because the mannequin has positioned model blocks that may inject the picture options into these blocks to realize seamless model switch. Moreover, because the mannequin tremendously reduces the variety of parameters of the adapter, the textual content management means of the framework is enhanced, and the mechanism can also be relevant to different attention-based characteristic injection fashions for modifying and different duties.

Immediate-Fashion : Experiments and Outcomes
The Immediate-Fashion framework is carried out on the Steady Diffusion XL framework, and it makes use of the generally adopted pre-trained IR-adapter as its exemplar to validate its methodology, and mutes all blocks besides the model blocks for picture options. The Immediate-Fashion mannequin additionally trains the IR-adapter on 4 million large-scale text-image paired datasets from scratch, and as a substitute of coaching all blocks, updates solely the model blocks.
To conduct its generalization capabilities and robustness, the Immediate-Fashion framework conducts quite a few model switch experiments with varied types throughout totally different content material, and the outcomes will be noticed within the following photos. Given a single model reference picture together with various prompts, the Immediate-Fashion framework delivers top quality, constant model picture technology.

Moreover, because the mannequin injects picture data solely within the model blocks, it is ready to mitigate the problem of content material leakage considerably, and due to this fact, doesn’t have to carry out weight tuning.

Transferring alongside, the Immediate-Fashion framework additionally adopts the ControlNet structure to realize image-based stylization with spatial management, and the outcomes are demonstrated within the following picture.

In comparison towards earlier state-of-the-art strategies together with StyleAlign, B-LoRA, Swapping Self Consideration, and IP-Adapter, the Immediate-Fashion framework demonstrates one of the best visible results.

Last Ideas
On this article, we’ve talked about Immediate-Fashion, a basic framework that employs two easy but efficient methods to realize efficient disentanglement of content material and elegance from reference photos. The InstantStyle framework is designed with the intention of tackling the problems confronted by the present tuning-based diffusion fashions for picture technology and customization. The Immediate-Fashion framework implements two very important methods: A easy but efficient method to decouple model and content material from reference photos throughout the characteristic area, predicted on the belief that options throughout the identical characteristic area will be both added to or subtracted from each other. Second, stopping model leaks by injecting the reference picture options solely into the style-specific blocks, and intentionally avoiding the necessity to use cumbersome weights for fine-tuning, typically characterizing extra parameter-heavy designs.

